工作时间
早9:00 - 晚18:00
周六日休息
有限公司-首页")

IBM SPSS Statistics
发现数据洞察,帮助解决业务和研究
IBM® SPSS® Statistics 是强大的统计软件平台。 它可提供用户友好型界面和强大的功能集,让您的组织能够快速从数据中提取切实可行的洞察。 高级统计程序有助于确保高准确度且高质量的决策制定。 包含分析生命周期从数据准备和管理到分析和报告的方方面面。
直观的用户界面
使用拖放界面执行强大的分析,且无需编码经验。
高级数据可视化
构建可视化并轻松导出,以包含在多个文件格式中,便于有效地沟通结果。
自动数据准备
帮助确保数据清晰、组织正确且可供分析。
高效的数据调整
标识无效值,查看缺失数据的模式并汇总变量分布。
本地数据存储器
通过在计算机(而非云中)存储文件和数据来提高数据安全性。
判别分数分布
根据测量的特征对组进行分类。
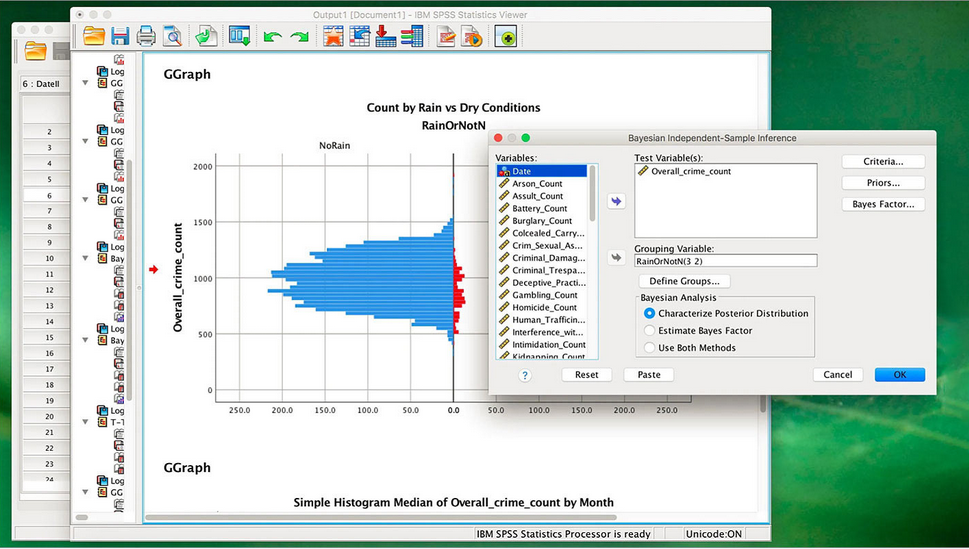
贝叶斯过程
估计参数的贝叶斯因子和后验分布。
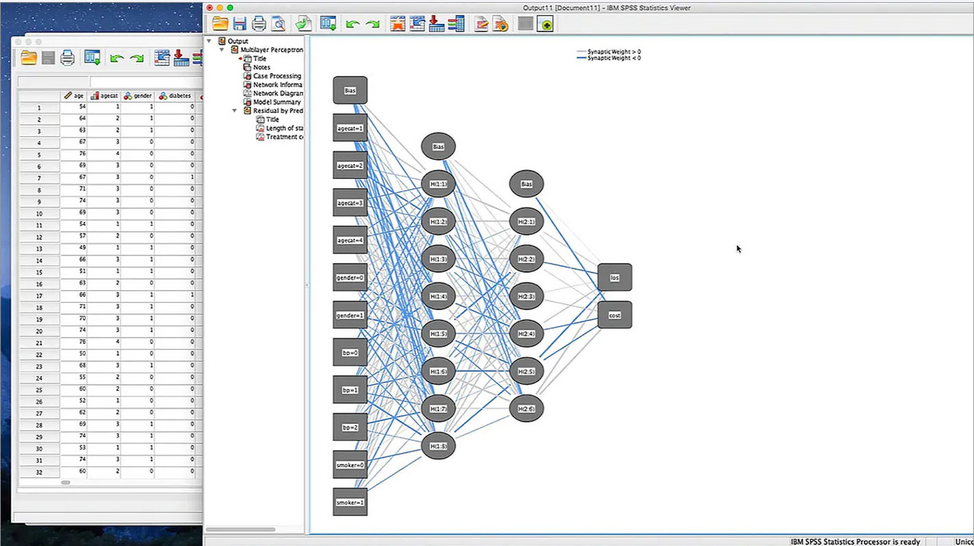
多层感知器 (MLP) 网络
使用神经网络模型预测或分类结果。
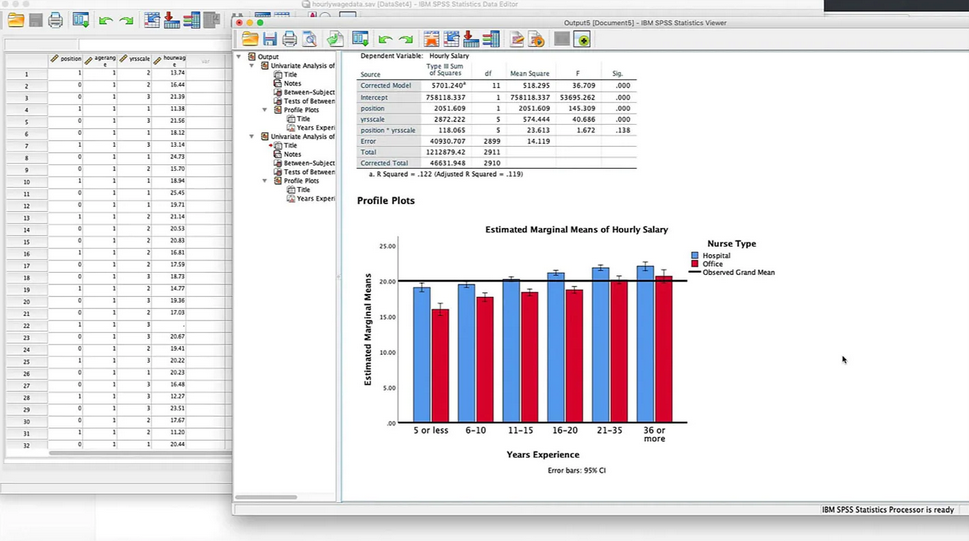
估计边际平均值
使用一般线性模型方法比较组平均值。
|
SPSS
Statistics Base 统计分析基础产品包 |
SPSS Statistics Standard 统计分析标准产品包 |
SPSS Statistics
Professional 统计分析专业产品包 |
SPSS Statistics
Premium 全模块统计分析产品包 |
产品简介 |
| Base | Base | Base | Base |
必需的基础模块,管理整个软件平台,管理数据访问、数据处理和输出,并能进行很多种常见基本统计分析。基本统计分析功能包括描述统计和行列计算,还包括在基本分析中最受欢迎的常见统计功能,如汇总、计数、交叉分析、分类比较、描述性统计、因子分析、回归分析及聚类分析等等。 |
| Advanced Statistics | Advanced Statistics | Advanced Statistics |
在分析数据时,除了基本的数据分析外,如果还想建立分析过程数据,就需要使用Advanced
Models,为顺序结果建立更灵活、更成熟的模型,在处理嵌套数据时得到更精确的预测模型,可以分析事件历史和持续 时间数据。具体功能包括:广义线性模型(GZLMS)、广义估计方程(GEES)、混合模型、一般线性模型(GLM)、方差成分估计、MANOVA、Kaplan-Meire 估计、Cox 回归、多因子系统模式的对数线性模型、对数线性模型、生存分析。 |
|
| Regression | Regression | Regression | 大量的非线性建模工具、多维尺度分析帮助研究人员进行非线性回归分析。它将数据从数据约束中解放出来,方便地把数据分成两组,建立可控制的模型及表达式进行非线性模型的参数估计,能够建立比简单线性回归模型更好的预测模型。 | |
| Custom Tables | Custom Tables | Custom Tables |
提供35
种单元和摘要统计量,能够更方便地显示多重序列数据,它能串接所有的维度,以在同一表格中显示包含不同统计量的各种变量。Tables
用更深入的分析,轻松地处理复选题与缺失值,用包括所有统计量、易于理解的表格来展现分析结果,通过完整的表格控制权,研究人员还可以自制表格,创造优美外观。 |
|
| Data Preparation | Data Preparation | 大量的非线性建模工具、多维尺度分析帮助研究人员进行非线性回归分析。它将数据从数据约束中解放出来,方便地把数据分成两组,建立可控制的模型及表达式进行非线性模型的参数估计,能够建立比简单线性回归模型更好的预测模型。 | ||
| Missing Values | Missing Values | 缺失数据会带来偏差或错误的分析结果,简单代入法或者简单的回归法都不能正确地填补缺失值,Missing Values Analysis 帮助研究人员在分析过程中排除数据中隐含的偏差,得出更精确的结论。Missing Values Analysis 用六种灵活的诊断报告来评估缺失值是否会影响分析结论,更好地了解它们的特性。 | ||
| Forecasting | Forecasting | Forecasting 是目前功能最强的时间序列分析工具,是分析历史资料、建立模型与预测未来事件的强有力的工具,能帮助研究人员做更好的预测。Forecasting 利用完备的时间序列提高预测能力,包括多重曲线拟合、平滑以及自回归方程估计。 | ||
| Categories | Categories | Categories 是优秀的对应分析程序,用启发性的二维图和感知图让您清晰地看到数据中的关系,使您可以更完整和方便地分析数据。Categories 提供非线性主成分分析来描述数据,并用图标清楚地展示数据中的关系,展示并分享动态、交互的分析结果,让您从分类数据中得到更丰富的信息。 | ||
| Decision Trees | Decision Trees | Decision Trees 模块基于数据挖掘中发展起来的树结构模型对分类变量或连续变量进行预测,可以方便、快速的对样本进行细分。它可直接在PASW STATISTICS 内做分类区分,用Syntax 撰写或用XML 来储存设定。使用Classification Trees 还可建立决策树来确认分组并预测结果,利用直觉式的树形图,颜色分类图,和表格协助研究人员轻松确认和评估区隔。 | ||
| Direct Marketing |
Direct Marketing
主要用来处理市场直销中的一些分析需求。目前提供RFM
客户评分,客户分群,目标客户轮廓概括,客户响应评分,不同营销行为响应测量等模型。将直销中常用的分析定制为不同的模块,市场研究人员可藉由Direct
Marketing 模块,以简单的方式进行简易直觉的分析,锁定高价值顾客,来进行各种营销分析。 |
|||
| Complex Sample | 如果使用了特别复杂的抽样方案,该模块可以计算复杂样本的统计数据,得到更精确的结果。它拥有专门的规划工具和统计方法,提供各种向导来制定取样方案或详细定义样本,并提供专门的技术来解决样本设计以及相伴标准误差,能够减少得出错误或误导性推论的风险。 | |||
|
|
Conjoint | SPSS Conjoint 是包含三个相互关联过程的一个系统,用于进行全特征联合分析。联合分析使研究人员了解消费者的偏好,或在一定产品属性及其水平条件下的产品评定。联合分析考虑研究时应包括的产品属性、考虑属性水平、产品卡片的数量,用正交设计生成一个包含适量产品卡片的正交主效果片段因子设计。 | ||
|
|
Neural Networks | 神经网络是一种模拟人类大脑处理信息的方式的简化算法模型。通过多个神经元层的输入输出运算给出一个判断结果。 | ||
|
|
Bootstrapping |
Bootstrapping
模块可以让您更有效的使用小样本量的数据,通过数据自身重采用的功能,让用户可以模拟大样本情况下的采样结果,从而对数据结构特征和偏差有更直接的认识。 |
||
|
|
Exact Tests | 为了确定现有变量之间的关系,研究人员经常首先查看交叉表和非参数检验中的p-值。本模块提供超过30 个精确检验涵盖了小型或大型数据集所有的非参数和分类数据问题。包括独立或相关样本的单样本、两样本和K-样本检验,拟合度检验,RxC 列联表独立性检验和联合测度检验等。 | ||
|
|
SamplePower * |
|
||
|
|
Visualization Designer * |
|
||
|
|
Amos * |
|
上一文章:IBM SPSS Modeler
下一文章:Simulink

Copyright 2021-2025 , SZ-UDATA.COM , All Rights Reserved 祐达数据科技(深圳)有限公司版权所有
地址:中国●深圳 福田区园岭街道华林社区八卦三路八卦岭工业区533栋621
电话:177 2283 7480(微信、企微同号) 邮箱:sz-udata@sz-udata.com
 粤ICP备2021173511号-1 sysadmin
粤ICP备2021173511号-1 sysadmin
